Datensicherheit
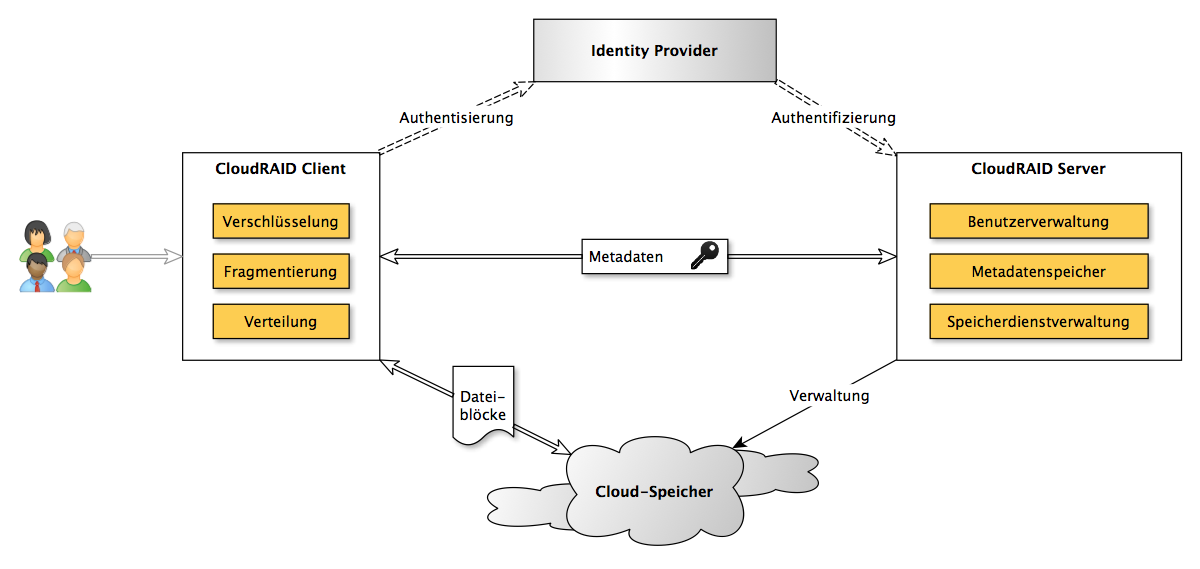
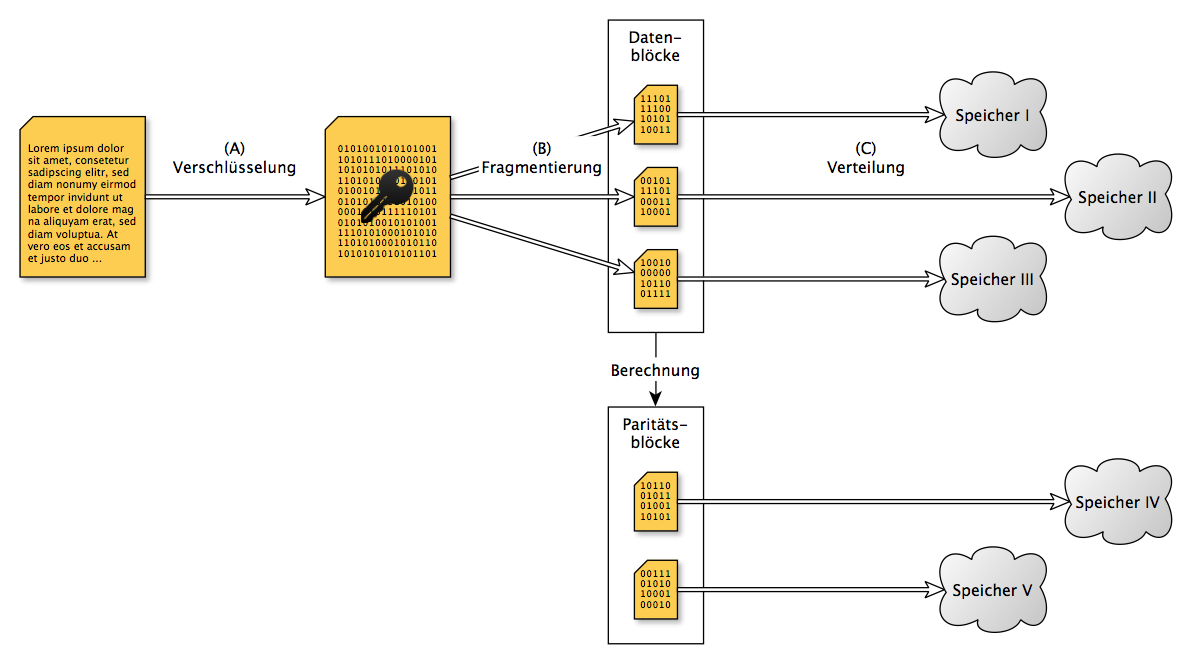
Jeder Speicheranbieter ist im Besitz von nur einem Fragment pro verteilt gespeicherter Datei. Aufgrund der Funktionsweise von RAID-Algorithmen können aus einzelnen Fragmenten keine Daten – oder Teildaten – extrahiert werden. Ein Angreifer müsste sich folglich auf mehrere der Speicherorte, bei jeweils verschiedenen Cloud-Anbietern, Zugriff verschaffen. Die genaue Anzahl dieser Speicherorte kann beim initialen Ablegen konfiguriert werden. Zudem ist die wiederhergestellte Datei kryptografisch verschlüsselt. Dadurch müsste der Angreifer zusätzlich im Besitz des geheimen Schlüssels, welchen nur der ursprüngliche Besitzer kennt, sein.
Datenverfügbarkeit
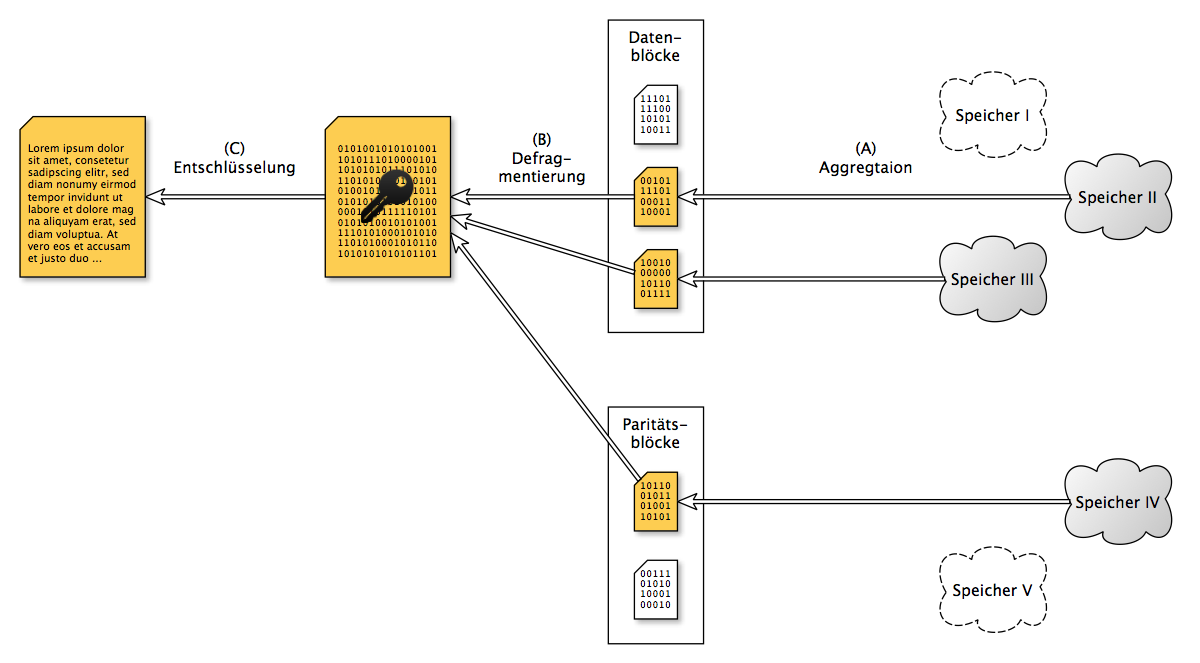
Durch die bewusst geschaffene Redundanz müssen zum Zeitpunkt der Wiederherstellung nicht alle Speicheranbieter verfügbar sein. Benutzer sind dadurch nicht länger von der Verfügbarkeit einzelner Anbieter abhängig. Darüber hinaus können aus den verfügbaren Speichern diejenigen gewählt werden, welche bestimmte, konfigurierbare Anforderungen erfüllen (z.B. geringe Kosten, hohe Übertragungsgeschwindigkeit, usw.). Kombinationen dieser Kriterien lassen auch komplexe Optimierungen zu.